Overview (Why?)
These agent pools are designed to solve many problems while also reducing cost and increasing resource efficiency. Not only does it provide a framework for the standardization of build/test agents, it provides a central point of contact for management.
By taking the burden of agent management off of the development teams, it allows them to take time that would have been spent updating/fixing/maintaining their agent pools and use it to delight our valued Medtronic and CareLink customers with faster features and bug fixes.
There are numerous AWS accounts that have agent pools residing inside that are either seldom being used or not being used at all. All the while they are racking up infrastructure cost because they're still on and running. The managed agent pools designed here will auto-scale based on usage. Meaning, as more developers run tests and builds the pool will continue to add more agents/servers to meet those demands. As utilization drops (e.g. at the end of the work day), the pools will gradually scale back down to conserve organizational cost.
Finally, when there is something wrong with the agent pools in the current self-managed paradigm, developers must take even more time from being productive to figure out what broke, how it broke, and what needs to be done to fix it. Either that, or they open a ticket with another team who might get to it in days or weeks due to their own backlog. The Developer Experience Team's task is to provide a joyous experience being a developer in CRM/CRHF, and to provide frameworks, tools, and services to make them even more productive and happy.
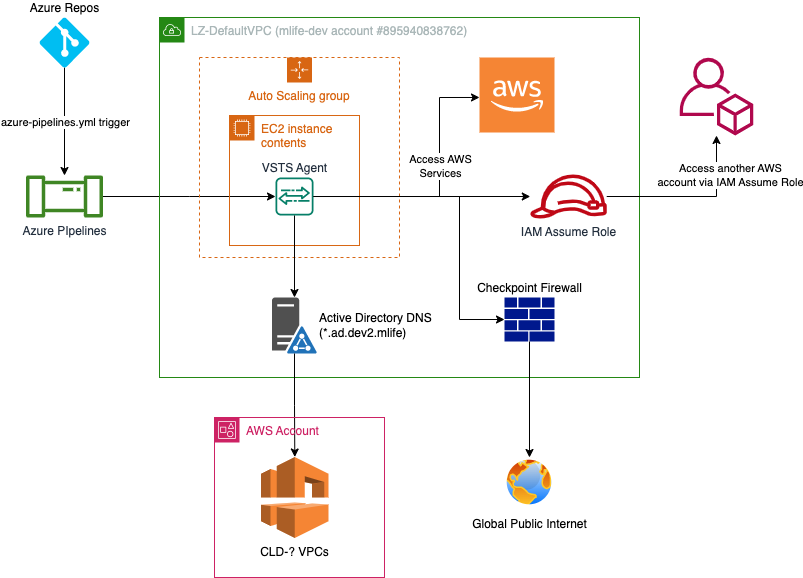
How do they work?
In a nutshell, an agent pool is made up of VSTS Agents. Each agent resides on an EC2 instance, and each EC2 instance has multiple VSTS agents. This is in effort to maximize the utilization of the server. When a job is sent to the pool, typically via Azure Pipelines, an agent is assigned and begins the work. The EC2 instance reports to CloudWatch how many agents it has available and how many are being used.
The EC2 instances are managed by an EC2 Autoscaling Group, and each group is assigned an Azure DevOps Agent Pool (it's a 1-to-1 relationship). The autoscaling group has dynamic scaling policies based on the agent metrics described at the end of the previous paragraph. As more agents are being used, the usage metrics go up. Once they trip the threshold, the alarm triggers and causes a scale-out event. The scale-out event adds more EC2 instances to the group, and the instances create and register more agents with the Azure Agent Pool. The scale-in event works the same way, but it triggers when usage drops below a threshold rather than above. These thresholds and policies will be refined over time.
Architecture