Introduction
To generate soup reports, the information on soup items are maintained in a soupinventorydata database in azure cosmos database. The information in these cosmos database gets added in two ways - automatically ( through artifact feeds ) and manually (through central repo)
Following section describes how soup inventory data can be added
How soup information is added into soupinventorydata database through artifacts feed (automatically)
According to the P&P artifact feeds are to be leveraged in order to use soup items in the solutions developed. Please refer the document here to read about the artifact management P&P. Read the document here to read about how to add soup artifacts to your solution
A pipeline is scheduled to run daily at midnight UTC, which scans all the artifact feeds present inside all projects in the organization (both project level and org level).
The pipeline has script to find the artifacts that gets added/updated and extract usable data and update the soupinventorydata database
To see the details of the implementation of the utility go here
How to Add soup information into soupinventorydata database through soupinventory repo (manually)
An alternative way is available to manually add the soup information into soupinventorydata database. A central repo on soup item information is stored here. This repo can be used to supplement additional information of soup items.
- Goto the repo here
- Create a branch from the repo
- Goto soup folder
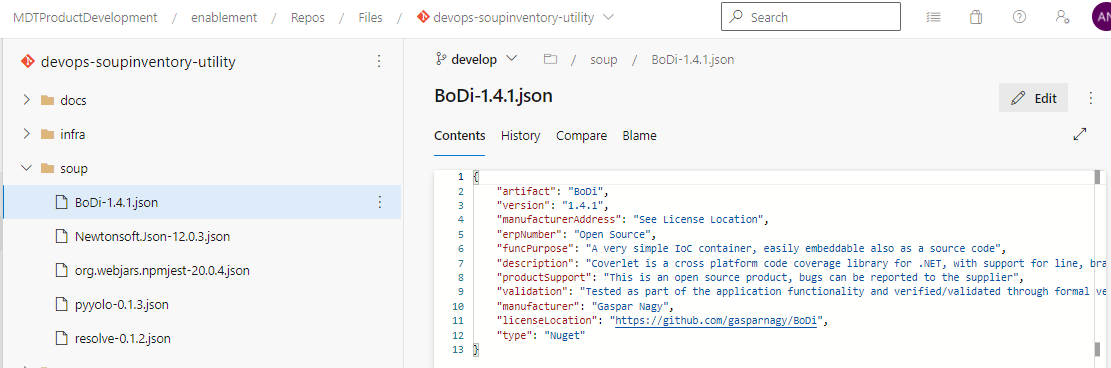
- Add the information for soup item
- This can be done by adding a new json file with name in the following format
- {soupitemname}-{soupitemversion}.json (intention is that file should be unique for an artifact and its corresponding version. This is just a recommended format, you can change the format if you face any issue, just make sure that the filename is unique and identifiable )
- create a pr which then has to be approved by Energizers team
A pipeline is created which gets triggered on merge to soupinventory repo. This pipeline has script to parse the files inside soup folder and update the database
The pipeline has script to find the information that gets added/updated and extract usable data and update the soupinventorydata database
To see the details of the implementation of the utility go here
Things to remember
- The soup information file should be a valid json
- If you find that the information fetched automatically is not accurate or you need to tweak it to a way you need, use the soupinventory repo flow to change the existing data. Update the value of the field you wish to update